Lock timings (II)
The std::shared_lock (aka the readers-writers lock) is more complex code than the std::mutex. As such, I would expect it to be slower, unless (maybe):
- it is protecting a structure which is read more often than written. Writing is serialized anyway but reading can be parallelized.
- the read contention is high
- the critical section to be protected is sizeable
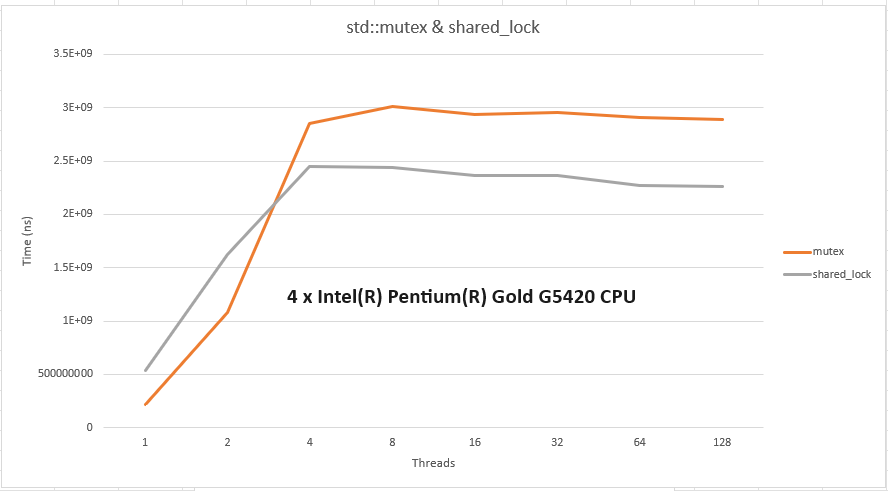
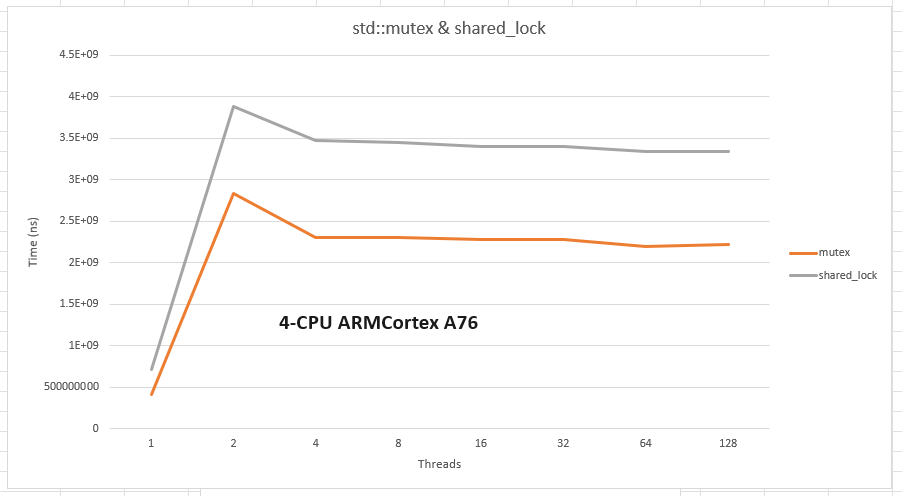
Here is a set of measurements for reading with the shortest critical section I can think of (incrementing a counter):
-
x86: even at a low contention of 3, the shared_lock wins. I suspect the inflection point happens as soon as contention spills across the CPU sockets (2 in this case) as a result of the cache line plays becoming more expensive.
-
ARM: the case seems less clear. Here the mutex is faster all the time. I suspect this is due to different/higher barriers costs for ARMs ( /barriers-costs/1 ). This is for the smalest critical possible; with a longer critical section (e.g. fishing for some data out of a container) the shared_lock should outperform the mutex for high reader contention (no measurements yet for this case) for reading.