Some lock timings (I)
Made a set of measurements for various lock types. These can be used as a guide and not as full substitute for mesurements in a given software context & hardware:
- these measurements are only indicative for a different architecture.
- these measurements are even less useful out of the software context where used (i.e. what is the lock used for; how long is it held; etc)
With above caveats in mind, I think these are fair inferences from the data:
- wait-free is best (duh) but there are probably not many places where it can be used. Very cache-friendly too.
- lock-free is next best (but keep in mind the above note on software contexts which might make it underperform, say, mutexes; see e.g. /lockfree-gone-wrong/1)
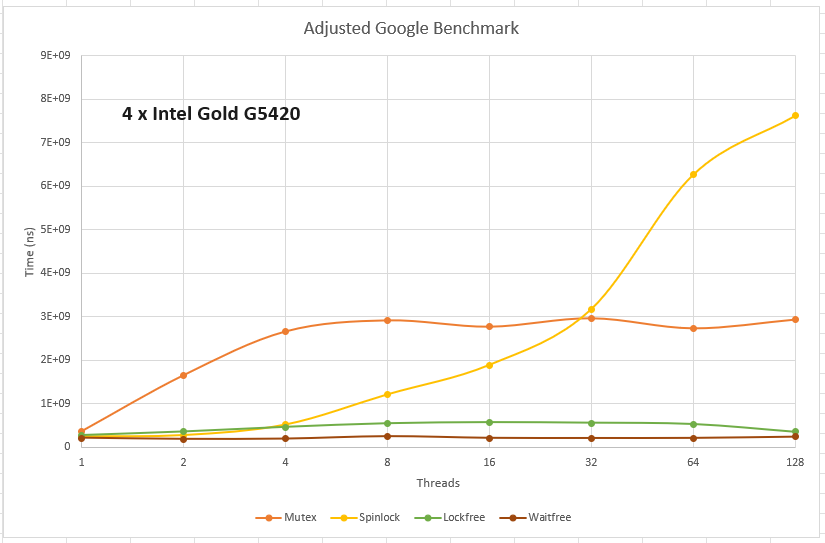
- the std::mutex is pretty constant with any contention level once contention reaches 2xCPU threads (Intel); or more than once CPU (ARM)
- pthread_spinlock_t: sad but not hopeless. Definitely not the right type of lock for this particular test but likely beating the mutexes in a low-contention very-short critical section usage.
- They are rather CPU-intensive and cache-coherence-destructive - though YMMV with other hardware flavors than the ones I used. And it is not scaling well with contention. Not at all - the time spent per-thread is basically constant. In my tests, test completion times for spinlocks were human-noticeably slower than mutexes (and everyting else) for high contention.
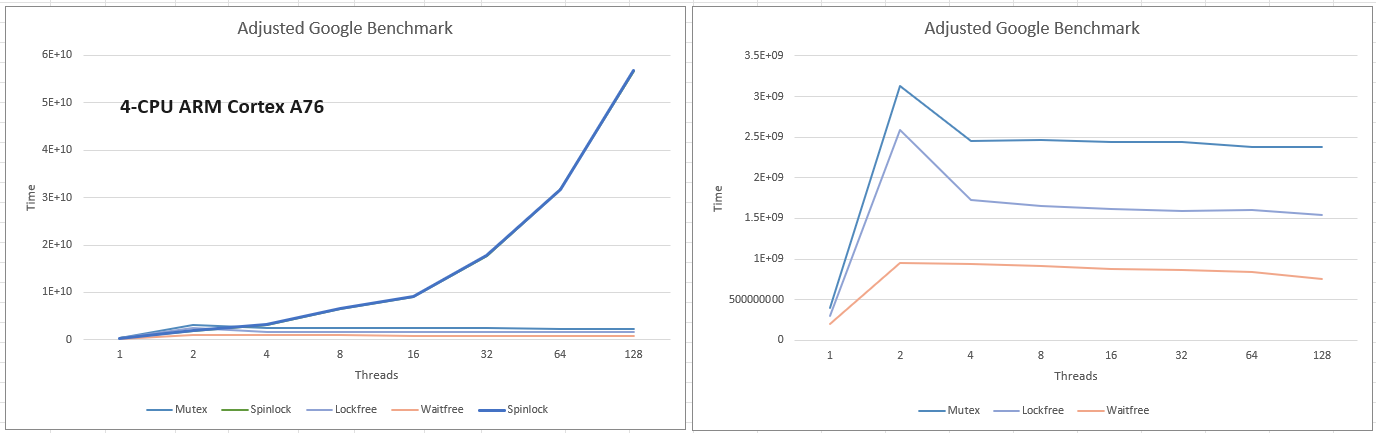
- ARM: it loses any edge over the mutex at contention levels above 3 on a 4-CPU machine, a much faster edge loss than x86. Do not use in a real setup unless it measures favorably against a mutex.
- An ARM core has lower performance than an Intel one (I have been told so).
- On ARMs, CAS is performing better than atomic increment ops.
- Intel: while beating the std::mutex in low-contention environments, pthread_spinlock_t lose their advantage as soon as the contention keeps growing over a given threshold. In this particular test, on a 4-CPU Intel machine, the mutex wins if contention goes over 32 threads.
- Custom-written spinlocks could behave better than mutexes: Fedor Pikus’s one has very good performance2. Or the Rigtorp’s one3. It is not a simple task4 to devise one and IMO the improved performance stems from periodically yielding/sleeping (cheating a bit?) but I have no measurements yet; and the best sleep algorithm is likely quite dependent on the CPU flavor and generation.
- Still, it could behave better than mutexes for short critical sections, the hardware being used and the contention level; must mesure with the real code to confirm.
- Here is the Intel damage:

Another note: Microsoft must have run similar tests, on Intel, years ago. It combined both the spinlock and the mutex into a CRITICAL_SECTION object. It is now used in the stdio area and the spin defaults to:
#define _CORECRT_SPINCOUNT 4000
So it spins 4000 times before deciding to sleep on the mutex. Without apropriate measurements I should have no opinion but: I am not sure this is still appropriate for nowadays architectures. IMO that fixed spin number should have been scaled inversely to the number of CPUs; then maybe a contention-dynamic spin value is needed - spin less with increased contention.
As for ARM, there does not seem to be much to gain with a CRITICAL_SECTION.