ARM - why not to construct a shared L3 cache with a loooong line
Summary:
- keeping the L3 cache line size the same as L1/2 is a good idea
- a line of 256 bytes is too long: fetching 256 for a line instead of 64 has a time/bandwidth extra cost; false sharing gets really annoying.
Here is how 4-cores CPUs for Intel and ARM behave when the cache is churned hard. Both Intel and ARM caches have 64 bytes lines and 3 levels:
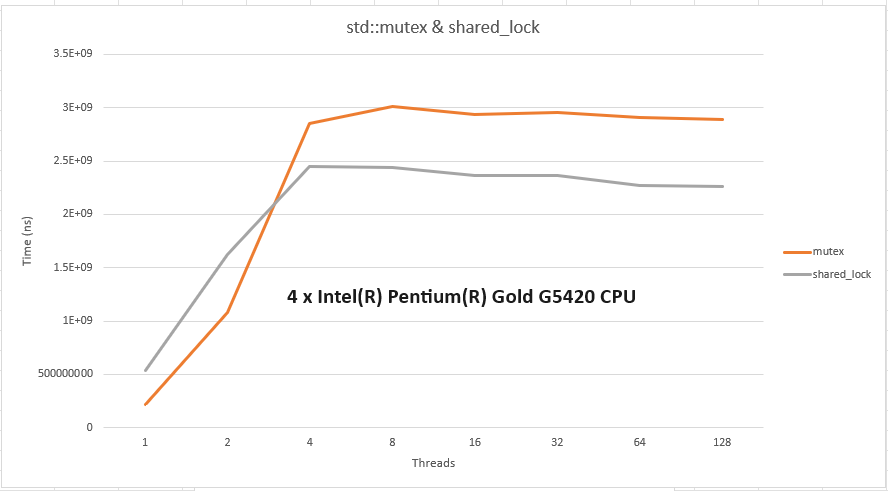
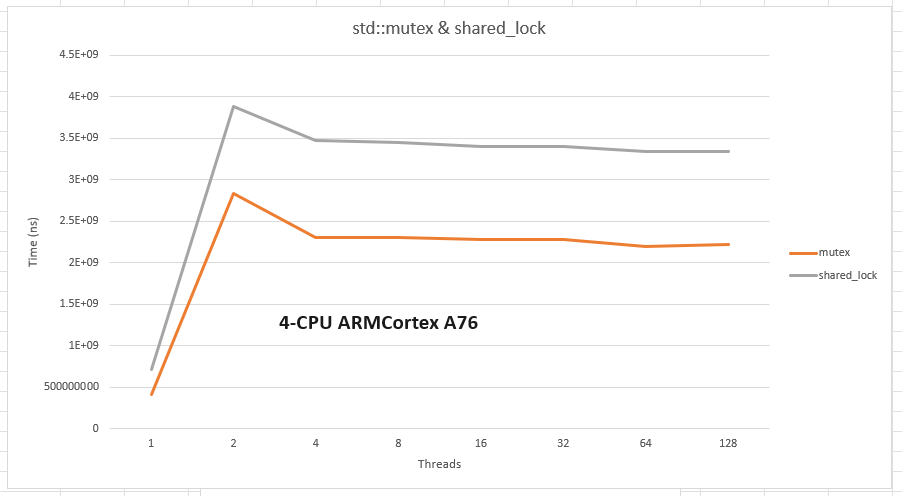
The ARM is kind of struggling, to the point that a piece of software optimized for Intel has to be changed significantly:
- a Intel-optimal locking mechanism is not optimal anymore on ARM.
- structures have to be realigned.
- accordingly, algorithms running on these structures may have to be changed as well.
Luckily, the stdlib reports (correctly) a huge offset is needed on this ARM to avoid false sharing, so at least you have a hint where the issue is:
Offset Intel ARM
--------------------------------------------- ------ ------
std::hardware_destructive_interference_size 64 256
std::hardware_constructive_interference_size 64 64
Per cppreference1, above values are for L1 (256 for that cache level !?):
“These constants provide a portable way to access the L1 data cache line size”
I think the reason of this poor performance is more likely the L3 cache, optional for ARMs2:
“All the cores in the cluster share the L3 cache”.
Written on June 1, 2024