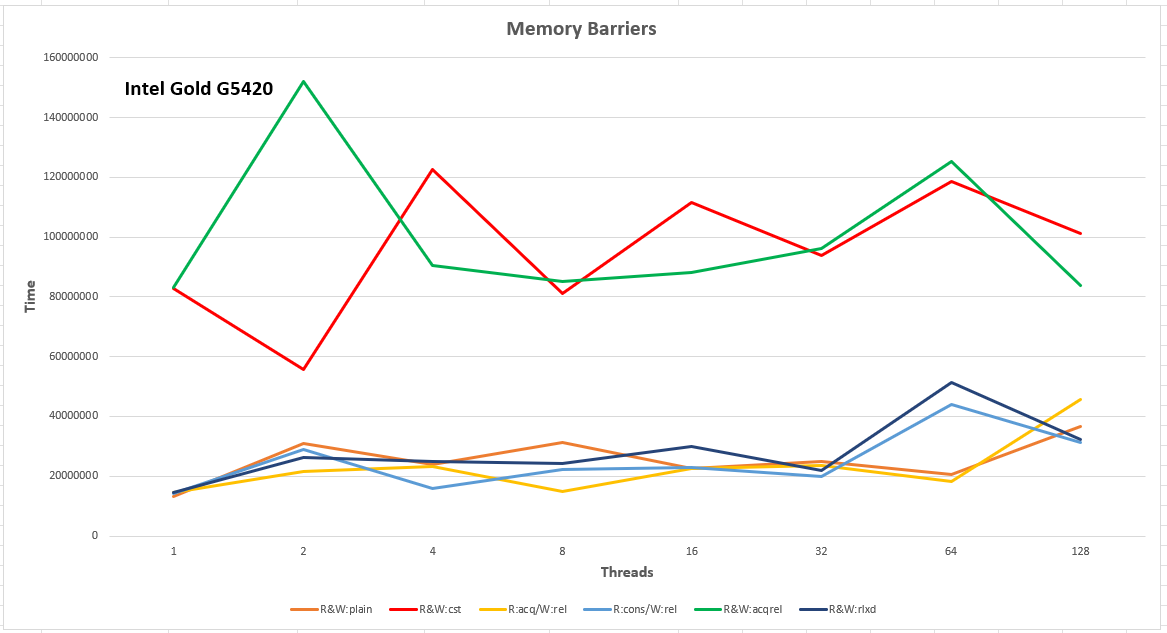
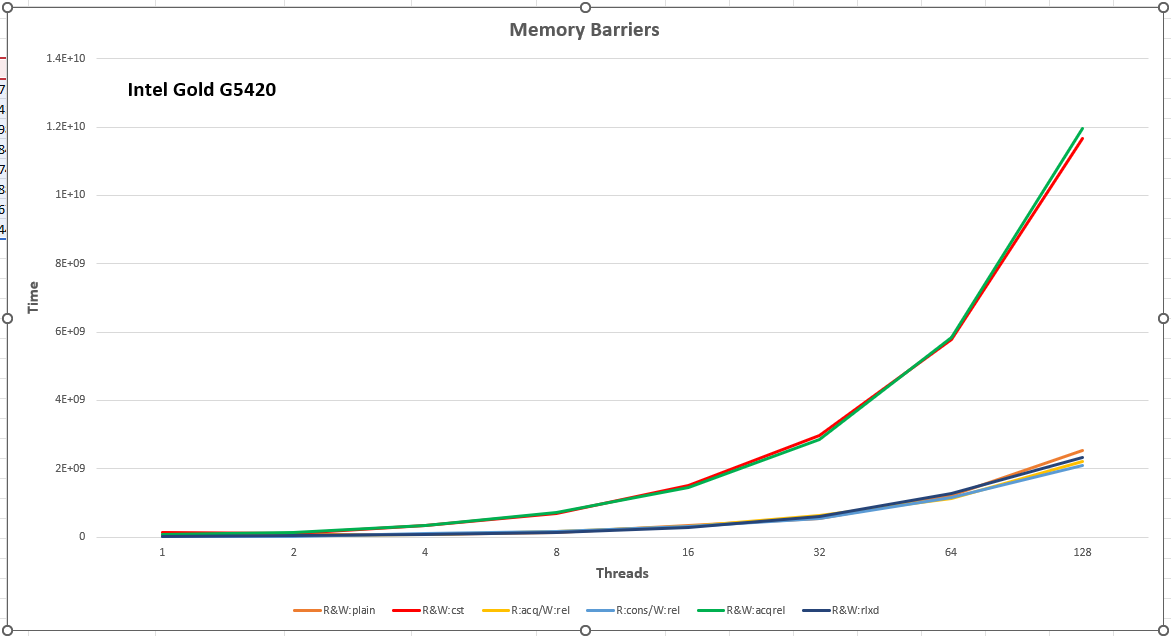
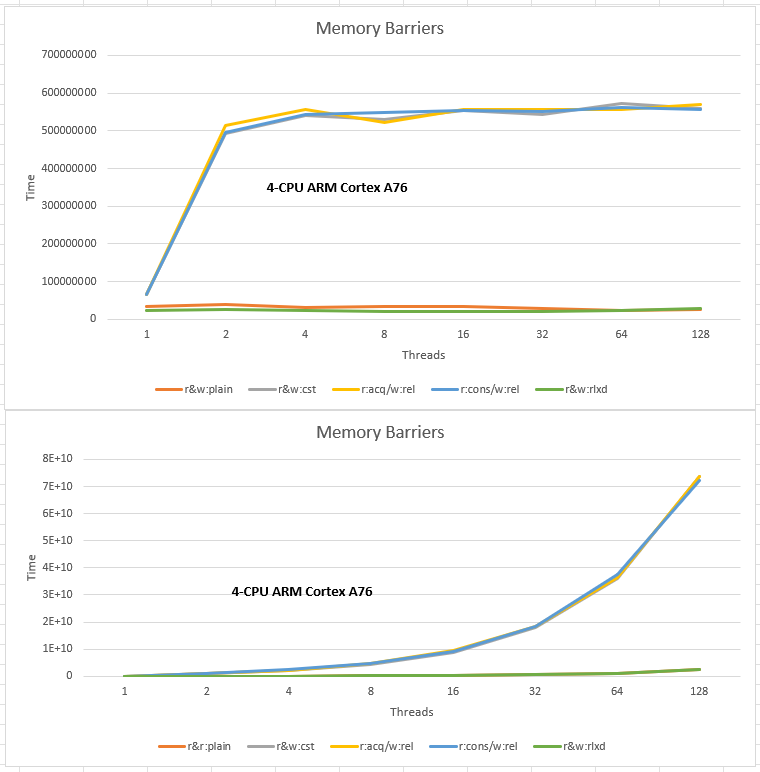
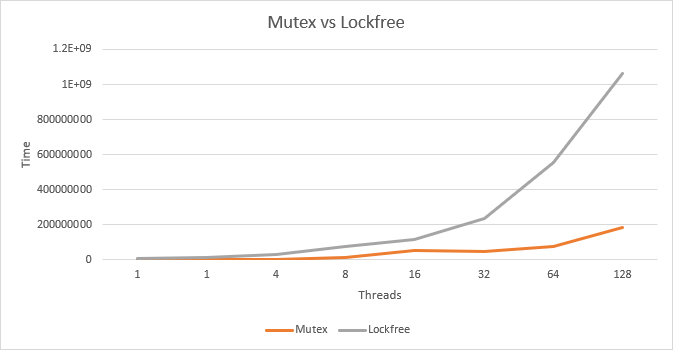
A note on the performance of move-constructing
Everybody likes to move it move it, including King Julien of Madagascar cartoon fame. Inconditionally. But I heard at least twice that move-constructed objects can negatively impact performance (when compared to plain copy-constructed objects that is). There is an extra memory diffusion which does worsen data access. But I have not been shown any hard data nor could I find any.